Remodeling the on-prem upgrade process at Hyperscience
⏱ 6 minute read
Overview
At Hyperscience, the on-premise upgrade process for enterprise customers to new versions of our platform was complicated, error-prone and took a very long time. Our goal was to reduce the time to value for enterprise customers.
My role
As the senior product designer working on system integrations – most, but not all of the upgrade experience ownership fell into the teams I was working with. I had to:
- Map out the entire upgrade process from the perspectives of our customers, our implementation specialists that managed the upgrade process and TSEs that helped with the tactical parts of an upgrade.
- Gather more information on all the different problems customers were experiencing.
- Map out the technical landscape of an upgrade process – figure out what was required for our platform to get upgraded, how our machine learning models impacted the whole experience, what were the technical dependencies and challenges on the customer front and how it all fits together.
- Frame the problem clearly and coherently and work with product managers and stakeholders to break it down into manageable projects that each deliver value.
- Facilitate conversations and potential solutions with a multitude of different teams across the company that had overlap with the problem space.
- Design and help ship an MVP solution with a given set of technical and time constraints.
Exploring the on-prem upgrade problem space
To get a better understanding of the problem, we mapped out how our system worked and talked to different people, both internal and external, to tell us about their upgrade experience.
Mapping out the technical landscape
Due to the nature of the product, our on-prem platform had a lot of technical complexities – machine learning models required training with customer data before they could get up and running and that meant there was a lot of up-front work required from the client before they could see any value. We mapped out exactly how that impacted upgrades.
Talking to Implementation Managers
Our IMs were responsible for owning the upgrade process – once a client upgrade was initiated, it was their responsibility to see it happen. They told us that:
- New infrastructure took clients a long time to procure
- It was difficult to allocate and dedicate time and resources to new model training
- Due to the multitude of people involved in an upgrade from a client perspective, it took a lot of time to plan and organise
Talking to TSEs
We talked to our technical support engineers, who were the folks responsible for helping clients with the tactical complexities of performing an upgrade. They provided a unique perspective on the problem:
- Clients sometimes did not have the necessary infrastructure to perform an upgrade
- Some clients did not have the required know-how to install scripts, manage databases or use CLI
- Model training was very unclear and confusing due to a lack of transparency on how it exactly worked and an overall high technical complexity
- The correct training data was very difficult to acquire due to privacy and security concerns. Not all people in an organisation were cleared to handle personal data.
Talking to Customers
We spoke to a few different personas from the client’s side – Product Managers and Sysadmins – they told us that:
- Model training was a cumbersome and extremely difficult process due to them having to do it on a lower environment
- Model training was a black box – it was unclear how long the trainer needed to run for and our model compatibility was a mystery
- We released too frequently. Hyperscience had a 3-month release cycle, while most of our clients upgraded these types of vendor software once, at most twice a year
- The immediate value of a newer version was not obvious
Producing a journey map

Approach
After gathering the qualitative information, we synthesised all of our findings and did several workshops – that helped us wrap our heads around the different issues assign priority.
Ownership and team distribution
The discovered issues fell into the ownership of many teams, so improving the experience meant that several product designers, product managers and engineering leads from different squads had to come together and collaborate.
Breaking down the problem set
After getting together with the different teams, we defined and broke down the problem set into several project initiatives that tackled various pain points.
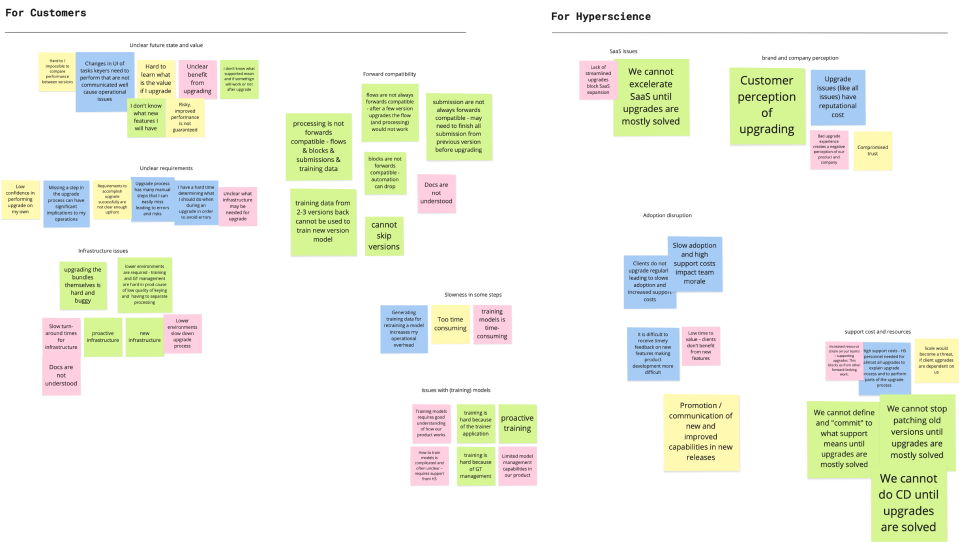
Clustering & Prioritization
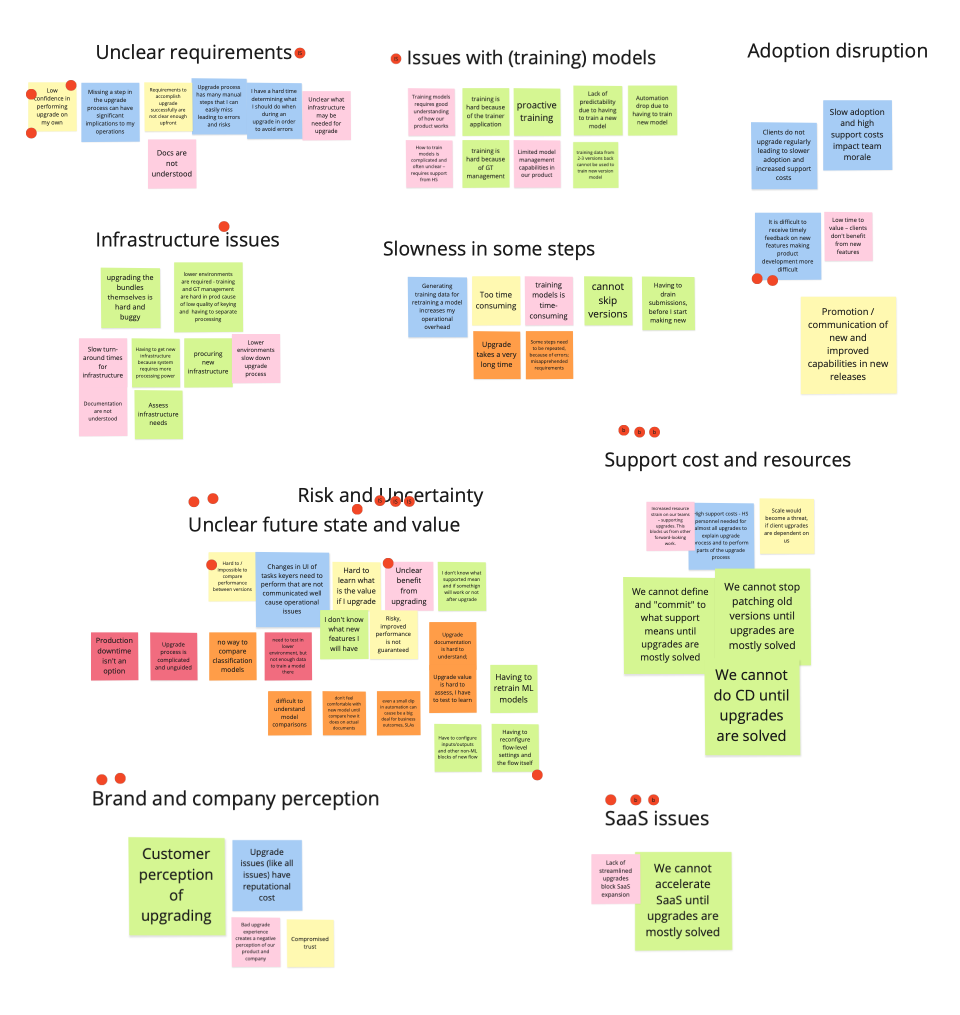
Forward-compatible models
After we managed to cut up the issues into logical chunks, we figured out that one of the things that would have the most positive impact on our upgrade experience is making our models forward-compatible with newer versions of our platform.
I was responsible for designing a way to alleviate this particular pain point – remodelling the experience of our platform so that users could still use their old machine-learning models after a platform upgrade. This meant that they would not have to train new models right away.
A bit of context about the Hyperscience platform
A Flow in Hyperscience is what makes document processing work – it ingests, processes and outputs documents.
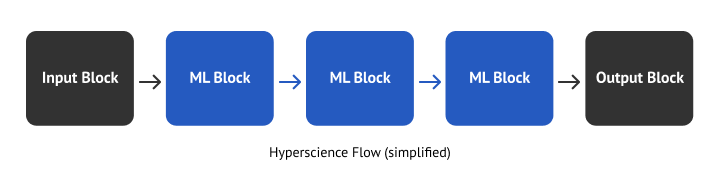
Flows are comprised of Blocks that represent a certain step. Flows also feature Releases and Layouts which control the types of documents processed.
This is where machine learning models come in.
- Models are dependencies of layouts and releases
- (ML) Blocks need models to work
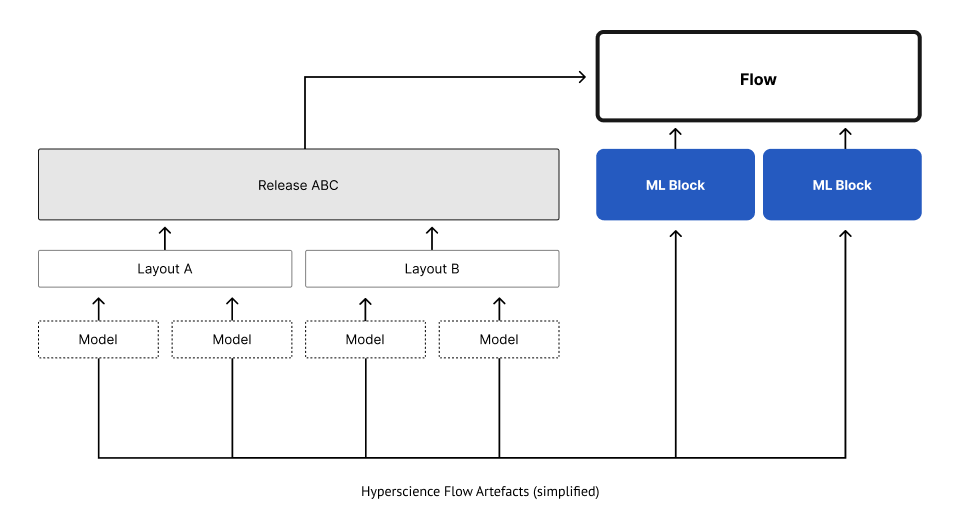
Diving into the model compatibility problem space
Forward-compatible models meant that versions N-1 and N can co-exist in the Hyperscience platform.
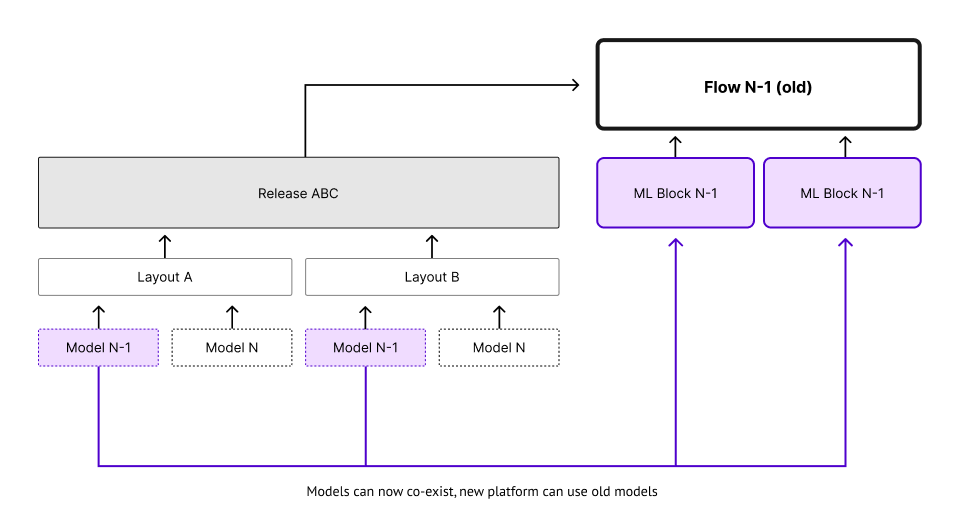
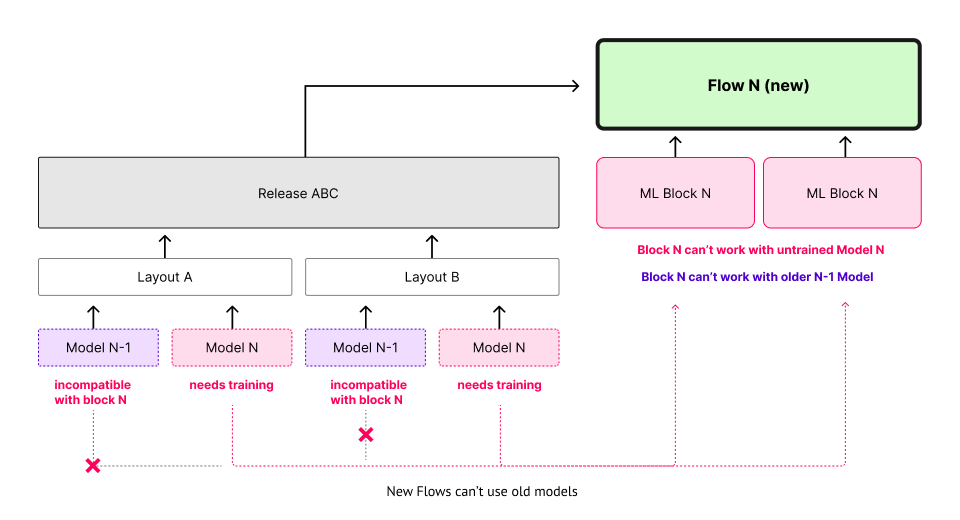
However, this props up new challenges:
- Layouts and releases have no concept of or require model versions
- Certain blocks require certain model versions
Solution
Having now a good understanding of the problem and its specifics, I did the following:
- Looked closely at which areas of our system and experience this change would impact – Flows, Releases and Model Management
- Ensured that we signal to users that their old models still work with the new versions of the platform
- Designed a feature addition to our Flows space that would expose a “Model Compatibility” feature, that would enable users to see that they need new model versions (perform model training) to work with the newer features (Flows) of our platform
- Eliminate the need to expose and communicate model versions to customers
- Expose a “Flow Compatibility” feature on the Model page, so users would have information about which Flows a Model can be used in.
- Establishing a relationship between Flows and Models set up groundwork and development foundations for a future model management space in our platform where users could see and easily manage versions, releases, training data, and compare accuracy.
This is what the new workflow would look like:

Outcome
- Deferring the need for model training when performing an upgrade breaks the whole process down into manageable phases
- Clients could upgrade the platform, have uninterrupted document processing (no downtime) with their old models and still benefit from some of the new platform features, ultimately having reduced time to value and perform model upgrades later, if and when they need specific new Model features
- This solution was a small step towards a more coherent model management scheme for our platform
Lessons learned
Cross-team collaboration is very tricky when there is a very broad problem on the table that impacts a multitude of teams – no clear ownership and priorities are difficult to set – but when you work to break the problem down into manageable chunks it becomes easier to tackle.
Thank you for reading!